Chioro bietet die Möglichkeit im Admin Menü Konfigurationen für den Zugang zu externen Datenquellen zu hinterlegen:

- Zugang zum Admin Menü
- Hier kann eine neue Konfiguration angelegt werden
- Liste der vorhandenen Konfigurationen. Diese können durch Klick auf den Namen editiert werden.
Neue Konfiguration
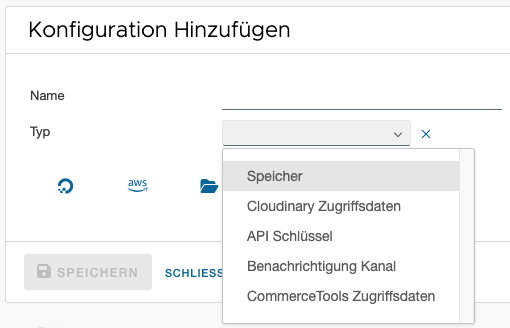
Nach Klick auf das Plus (2), muss ein Konfigurationstyp ausgewählt werden. Im Moment stehen URL, CommerceTools, Storage und Benachrichtigungs Kanal zur Verfügung.
Bearer Token
Ein Bearer Token speichert einen einzelnen HTTP-Authentifizierungstoken. Er wird überall dort eingesetzt, wo eine externe API eine Autorisierung nach dem Schema Authorization: Bearer <token> erwartet — typischerweise REST-APIs mit API-Key-basierter Authentifizierung.
| Feld | Beschreibung |
|---|---|
| Name | Eindeutiger Name der Konfiguration |
| Token | Der geheime Bearer-Token der externen API |
Basic Auth
Basic Auth speichert Benutzername und Passwort für HTTP-Basisauthentifizierung. Der entsprechende Request-Header wird von Chioro automatisch im Format Authorization: Basic <base64(user:passwort)> gesetzt.
| Feld | Beschreibung |
|---|---|
| Name | Eindeutiger Name der Konfiguration |
| Benutzername | HTTP-Benutzername |
| Passwort | HTTP-Passwort |
GitHub Personal Access Token
Ein GitHub PAT (Personal Access Token) speichert die Zugangsdaten für ein Git-Repository auf GitHub. Dieser Konfigurationstyp wird insbesondere von Script-Bibliotheken und dem Flow-Backup benötigt, um Snapshots in einem Git-Repository zu lesen und zu schreiben.
| Feld | Beschreibung |
|---|---|
| Name | Eindeutiger Name der Konfiguration |
| Token | GitHub Personal Access Token mit repo-Berechtigung |
| Benutzername | GitHub-Benutzername (optional, aber empfohlen) |
Den Token kann man unter GitHub → Settings → Developer settings → Personal access tokens anlegen. Als Berechtigung genügt repo (Lesezugriff auf öffentliche und private Repositories) bzw. contents:write für Schreibzugriff.
Anthropic API Key
Ein Anthropic API Key speichert den Zugangscode zur Anthropic-API (Claude-Sprachmodelle). Er wird benötigt, wenn Claude-Modelle in Scripts oder Transformationen verwendet werden sollen.
| Feld | Beschreibung |
|---|---|
| Name | Eindeutiger Name der Konfiguration |
| API Key | Der geheime API-Schlüssel aus dem Anthropic-Dashboard |
Den Schlüssel findet man unter console.anthropic.com → API Keys.
CommerceTools
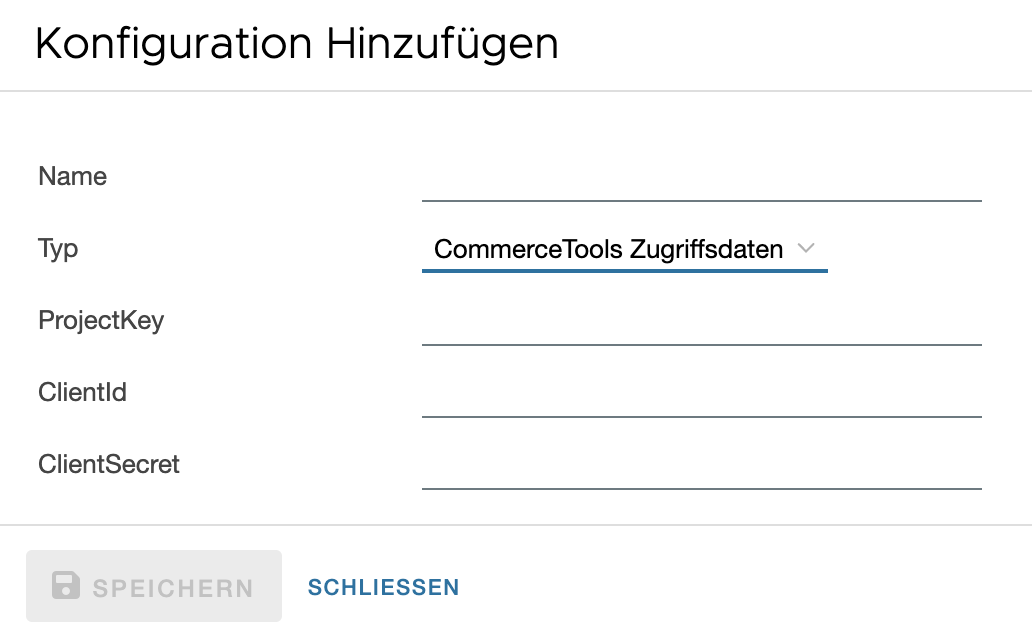
Die erforderlichen Zugangsdaten werden beim Anlegen eines Projekts auf der Commercetools Webseite generiert und müssen hier eingetragen werden.
Speicher
Unter Speicher steht die Möglichkeit zur Verfügung externe Dateisysteme einzuhängen. Diese Funktion wird über rclone realisiert, dort sind auch Informationen über die benötigten Einstellungen bzw. unterstützten Anbieter zu finden:
Es stehen mehrere Templates zur Verfügung und können per Klick auf den entsprechenden Button ausgewählt werden. Die Felder sind als Vorschlag zu verstehen, die erforderlichen Felder können, je nach Anwendungsfall, abweichen. Aus diesem Grund lassen sich mit ‘+’ Zeilen hinzufügen und mit dem Mülleimersysmbol löschen. Bei Problemen bitte an den Administrator wenden.
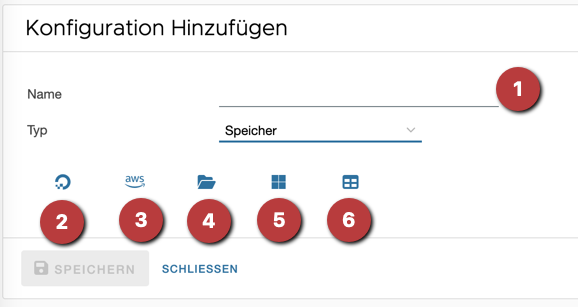
- Es muss ein Name vergeben werden
- Vorlage DigitalOcean S3
- Vorlage AWS S3
- Vorlage SFTP (File Transfer über ssh)
- Vorlage Microsoft Azure
- Leere Vorlage (‘name’ und ‘type’ müssen immer vergeben werden)
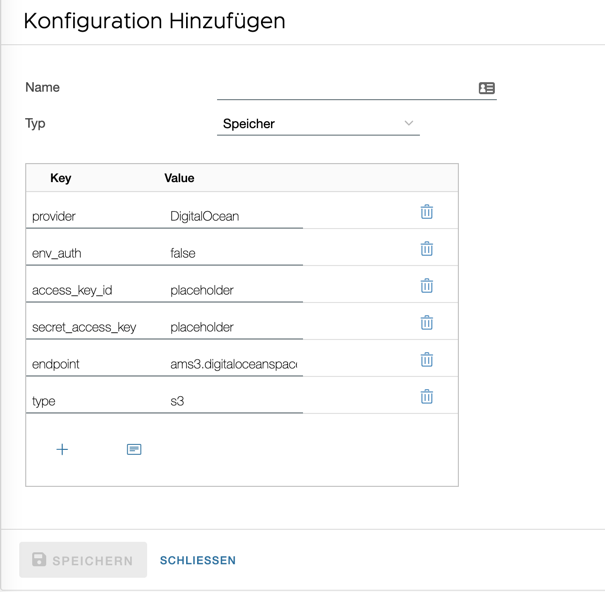
- Mit dem Plus-Symbol werden Zeilen hinzugefügt, also ein neuer key-value Eintrag erzeugt.
- Mit dem Template-Symbol werden die Vorlagen ein- bzw. ausgeblendet. Ein Klick auf eine neue Vorlage überschreibt alle vorhandenen Felder.
- Mit dem Mülleimer-Symbol werden Zeilen entfernt
Nach dem Klick auf Speichern versucht Chioro die neue Datenquelle einzuhängen. Bei Fehlermeldungen müssen die Einstellungen angepasst werden.
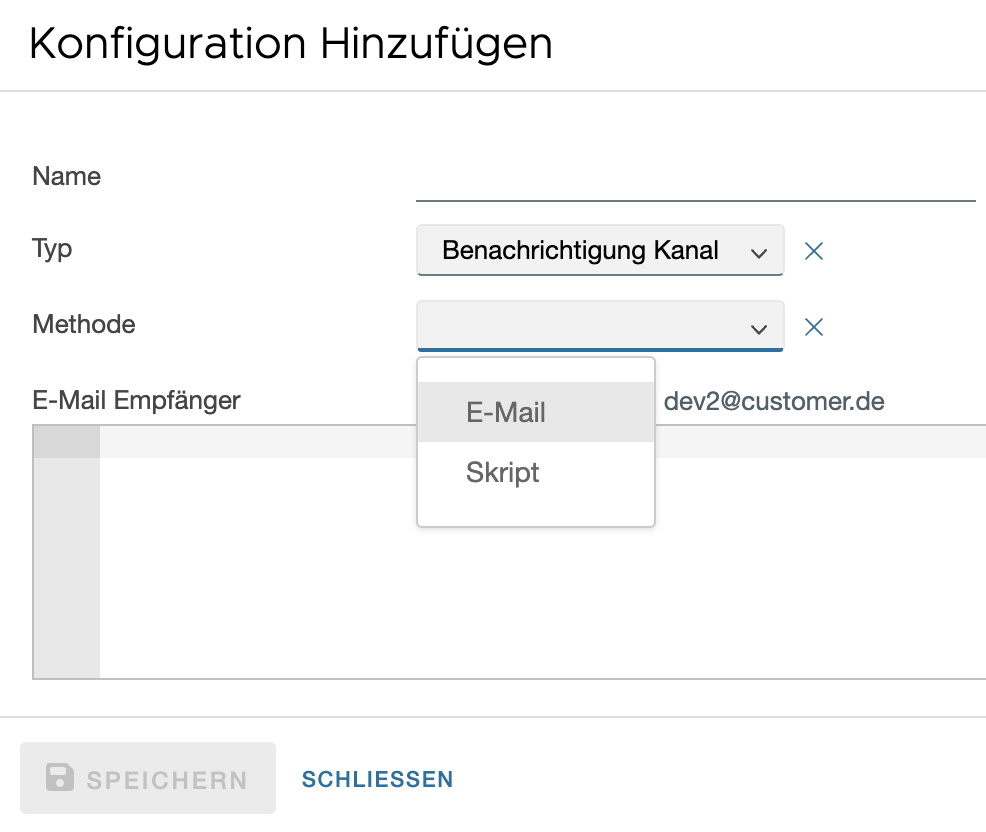
Benachrichtigung Kanal
Ein Kanal ist ein Ziel für die Benachrichtigungen, welche entweder vom Flow oder einer Operation ausgelöst werden können.
Die Standardmethode E-Mail verschickt, wie der Name schon sagt, eine E-Mail an die hinterlegten Empfänger anhand eines Handlebar Templates für den Inhalt der E-Mail. Für ein Beispiel mit einigen der möglichen Template-Variablen, einfach den Kanal mit leerem Inhalt speichern, dieser wird dann mit dem Standard Template ersetzt und kann danach beliebig geändert werden. Für dass zurückstellen auf das Standard-Template, einfach wieder mit leerem Inhalt speichern.
Das Skript ist für komplexere Benachrichtigungen gedacht, wie zum Beispiel das Aufrufen einer URL. Die Template-Variablen, welche es bei der E-Mail Methode gibt, sind unter kontext('TEMPLATE_VARIABLEN_NAME') zu bekommen. (TEMPLATE_VARIABLEN_NAME ist hier ein Platzhalter, bitte die Groß- und Kleinschreibung wie im E-Mail Template beibehalten.)
Mehr dazu unter Benachrichtigungen
OpenAI Provider
Ein OpenAI Provider hinterlegt die Zugangsdaten zu einem KI-Sprachmodell, entweder über die Standard-OpenAI-API oder über Microsoft Azure OpenAI. Mehrere Provider können angelegt werden, z.B. um verschiedene Modelle oder Azure-Deployments für unterschiedliche Anwendungsfälle zu verwenden.
Felder
| Feld | Beschreibung |
|---|---|
| Name | Eindeutiger Name der Konfiguration |
| Provider-Typ | OpenAI für die Standard-API oder Azure OpenAI für Microsoft Azure |
| API Schlüssel | Der geheime API-Schlüssel des Providers |
| Endpoint URL | Basis-URL der API (bei OpenAI automatisch vorbelegt) |
| Modell / Deployment Name | Bei OpenAI: Modellname (z.B. gpt-4o). Bei Azure: Name des Deployments im Azure-Portal |
| API Version | Nur Azure: API-Versionsstring (z.B. 2024-02-01) |
Anwendungsfälle
Jeder OpenAI Provider kann für einen oder mehrere Anwendungsfälle aktiviert werden. Jeder Anwendungsfall kann systemweit nur einem einzigen Provider zugewiesen sein.
| Anwendungsfall | Beschreibung |
|---|---|
| Attributextraktion | Wird für die KI-gestützte Attributextraktion in der Strukturierten Transformation verwendet |
| Attribut-Mapping | Wird für KI-Vorschläge beim Attribut-Mapping in der Listen-Transformation verwendet |
| Werte-Mapping | Wird für KI-Vorschläge beim Werte-Mapping in der Listen-Transformation verwendet |
| Script / Regel | Wird von Skripten über _gptFetcher.ask() ohne expliziten Config-Namen verwendet |
Wird ein bereits zugewiesener Anwendungsfall einem anderen Provider zugewiesen, erscheint ein Bestätigungsdialog. Nach Bestätigung wird der Anwendungsfall automatisch vom bisherigen Provider entfernt und dem neuen zugewiesen.
Prompt Einstellungen
| Feld | Beschreibung |
|---|---|
| Antworten cachen | Aktiviert den Prompt-Cache. Identische Anfragen werden aus dem Cache beantwortet, ohne die API erneut aufzurufen |
| Attribut-Mapping Prompt | Handlebars-Template für Attribut-Mapping-Anfragen. Leer lassen für den systemweiten Standard |
| Werte-Mapping Prompt | Handlebars-Template für Werte-Mapping-Anfragen. Leer lassen für den systemweiten Standard |
Verwendung in Regeln und Skripten
Das eingebaute Werkzeug askGPT steht im Regeleditor und in Script-Operationen zur Verfügung:
| Parameter | Pflicht | Beschreibung |
|---|---|---|
| Prompt | Ja | Die Frage oder Anweisung, die an das Sprachmodell gesendet wird |
| Provider-Konfig Name | Nein | Name der OPENAI_PROVIDER Admin-Konfiguration. Wird nichts angegeben, wird die Konfiguration mit dem Anwendungsfall „Script / Regel“ verwendet |
// Verwendet den Provider mit dem Anwendungsfall "Script / Regel"
askGPT("Übersetze ins Englische: " + wert)
// Verwendet einen bestimmten Provider anhand seines Namens
askGPT("Übersetze ins Englische: " + wert, "mein-provider-name")
Der Rückgabewert ist der Text der KI-Antwort als String.
Datenbank Zugriffsdaten
Die Konfiguration “Datenbank Zugriffsdaten” speichert eine JDBC-Verbindungszeichenkette (Connection String) zur Verbindung mit einer Datenbank. Die Zugangsdaten (einschließlich Benutzername und Passwort) müssen direkt in der JDBC-URL enthalten sein, da keine zusätzlichen Felder unterstützt werden.
Unterstützte Datenbanken:
- SQL Server
- MySQL
- PostgreSQL
Beispiele für JDBC-Connection-Strings (host, port, database, user und password entsprechend anpassen):
-
SQL Server:
jdbc:sqlserver://db.example.com:1433;databaseName=mydb;user=myuser;password=mypass;encrypt=true;trustServerCertificate=true -
MySQL:
jdbc:mysql://db.example.com:3306/mydb?user=myuser&password=mypass&useSSL=false&serverTimezone=UTC -
PostgreSQL:
jdbc:postgresql://db.example.com:5432/mydb?user=myuser&password=mypass&sslmode=disable
Diese Informationen werden anschließend vom Datasource Database Plugin genutzt, um SQL-Statements gegen die konfigurierte Datenbank auszuführen.