Was ist eine Flow Operation?
Als Flow Operation (oder einfach Operation) wird in Chioro ein Element eines Flows bezeichnet. Eine Operation empfängt Datensätze von ihrer oder ihren Vorgängeroperation(en), verarbeitet diese und schickt die verarbeiteten Daten an ihre Nachfolgeroperation(en). Vorgänger bzw. Nachfolger ergeben sich aus den Verbindungen (Pfeile) im grafischen Flow Editor. Lediglich Datenquellen bzw. Datenziele haben naturgemäß keine Vorgänger bzw. Nachfolger.
Es gibt Operationen um Daten zu importieren oder exportieren (Datenquelle und Datenziel), um Datensätze zu verändern (Transformation), Datensätze aus anderen zusammenzusetzen (Join), externe Services aufzurufen (Call), den Datenfluss zu steuern (Gate) und einiges mehr.
Eine Operation anlegen
Eine neue Operation wird angelegt, indem sie im grafischen Flow Editor von der Toolbox auf der linken Seite in den Flow gezogen wird.
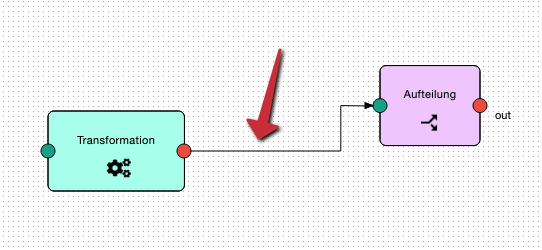
Um tatsächlich im Flow verwendet zu werden, muss sie dann noch über entsprechende Pfeile mit ihren Vorgängern und Nachfolgern verbunden werden:
Eine Operation löschen
Eine Operation kann auf zwei verschiedene Arten aus dem System entfernt werden. Achtung! Eine gelöschte Operation kann nicht wiederhergestellt werden! Aus diesem Grund erfolgt vor dem Löschen eine Sicherheitsabfrage.
Hinweis: Durch das Löschen einer Operation bleiben die Vorgänger- und Nachfolgeroperationen zunächst verwaist und müssen neu verbunden werden.
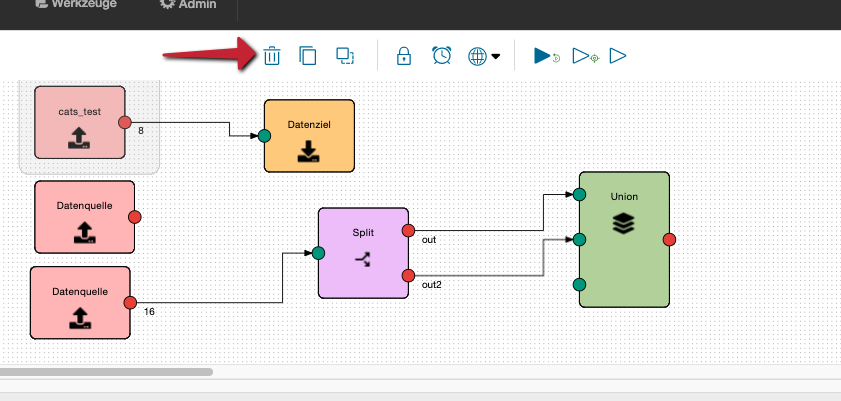
Löschen im grafischen Flow Editor
Im grafischen Flow Editor zunächst die Operation auswählen (markieren) und dan durch Klick auf das Papierkorbsymbol löschen.
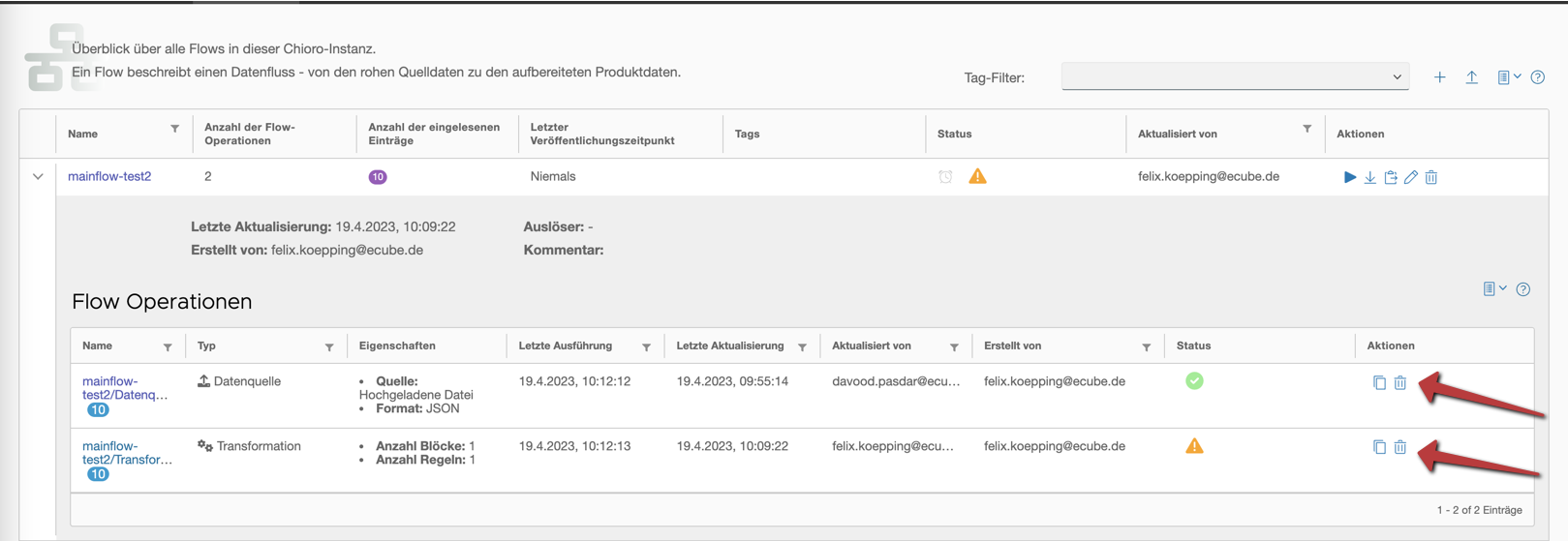
Alternativ kann eine Operation auch in der tabellarischen Flow Übersicht durch das Papierkorb Symbol gelöscht werden:
Eine Operation konfigurieren
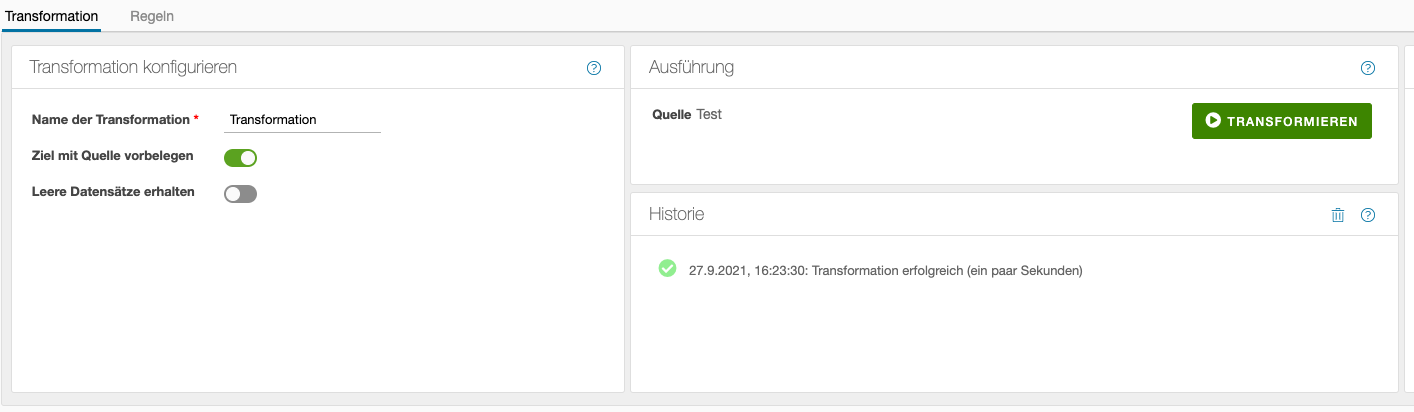
Konfiguriert wird eine Flow-Operation im Operation Editor, welcher sich direkt unter dem grafischen Flow Editor befindet.
Bei vielen Arten von Operationen umfasst dieser Bereich mehrere Ebenen, welche über Reiter am oberen Rand ausgewählt werden können. Der Inhalt der Ebenen hängt stark von der Art der Operation ab. Die erste Ebene ist aber bei allen mehr oder weniger gleich:
- Links befinden sich einige grundlegende Einstellung der Operation.
- In der Mitte ist der Button zum Ausführen der Operation und darunter die Historie.
- Rechts finden sich einige informative Metriken über die von der Operation erzeugten Daten
Der Inhalt der weiteren - per Reiter auswählbaren - Ebenen hängt wie gesagt von der Art der Operation ab. Meist findet sich hier aber die detailierte Konfiguration der Operartion, also z.B. die Definition der Transformationsregeln.
Allen Operationen ist jedoch gemeinsam, dass sie einen Namen besitzen. Dieser sollte aussagekräftig und hinreichend eindeutig sein (beides ist aber nicht zwingend).
Eine Operation ausführen
Eine Besonderheit von Chioro ist, dass jede Operation für sich alleine ausgeführt werden kann. Dies hat den großen Vorteil, dass - in Verbindung mit Chioros Vorschau Feature - iterativ an einer Operation gearbeitet werden kann, ohne jedesmal alle davor liegenden Operationen durchführen zu müssen.
Vorausetzung, dass eine Operation ausgeführt werden kann ist natürlich, dass die Daten der Vorgängeroperationen vorliegen. Hierzu müssen die Vorgängeroperationen alle wenigstens einmal ausgeführt worden sein.
Gestartet wird eine einzelne Operation im ersten Tab des Operation Editors. Dort finden sich nach der Ausführung auch grundlegende Informationen zur jeweiligen Operation, wie Historie und Ergebnis-Metriken (s.u.)
War eine Ausführung fehlerhaft, wird diese in der Historie entsprechend markiert. Die detaillierten Problembeschreibungen finden sich ggf. im Journal, welches im Data Exploration befindet (Beschreibung dort).
Fehlerhafte Flow Operationen
Falls eine Operation nach dem Ausführen einen fehlerhaften Status hat, wird dies im Flow Editor an den einzelnen Operationen rechts oben in der Ecke angezeigt.
![]()
![]()
![]()
-
 Die Aktion war fehlerhaft
Die Aktion war fehlerhaft -
 Die Aktion war teilweise fehlerhaft
Die Aktion war teilweise fehlerhaft -
 Die Aktion wurde abgebrochen
Die Aktion wurde abgebrochen
Metriken
Die meisten Operationen erstellen bei der Ausführung einige Metriken über das Ergbnis. Diese werden ganz rechts im Operations Editor angezeigt. Hier beispielsweise für eine Datenquelle:
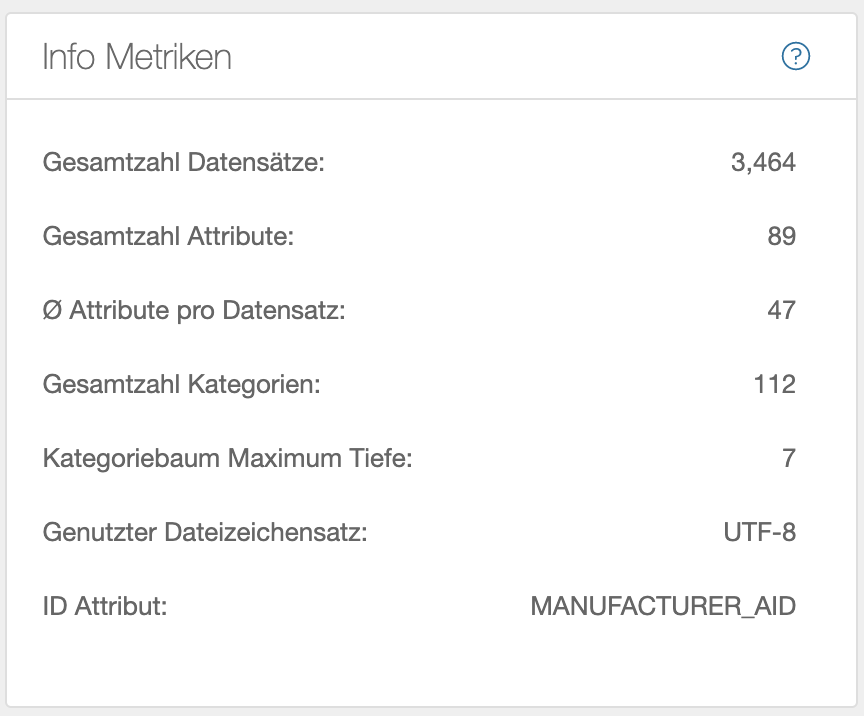
- Gesamtanzahl der Datensätze
- Gesamtanzahl der Attribute
- Durchschnittliche Datensätze pro Attribute
- Eigenschaften des Kategoriebaums: Wenn importierte Daten einen Kategoriebaum enthalten, werden die “Anzahl der Kategorien” und die “maximale Tiefe” des Baums aufgelistet.
- Der Zeichensatz, mit dem die Datei eingelesen wurde. Hilfreich als Feedback, wenn die automatische Zeichensatzerkennung beim Importieren einer Datenquelle ausgewählt wurde.
- Vorhandenes ID-Attribut zur Identifizierung der Datensätze
- DQI (Data Quality Index): Eine heuristische Qualitätskennzahl von 0 bis 100 für Operationen, deren Ergebnis sich gegen ein Zielschema prüfen lässt (z.B. die Attribut-Extraktion). Wird nur angezeigt, wenn die Operation einen DQI berechnet hat (siehe Abschnitt unten).
DQI – Data Quality Index
Der DQI ist eine strukturelle Qualitätskennzahl, die hilft, verschiedene Läufe einer Operation zu vergleichen — etwa nach einer Änderung am Prompt, am Modell oder am Zielschema. Er misst nicht, ob die extrahierten Werte inhaltlich korrekt sind, sondern nur, wie gut sie zum konfigurierten Zielschema passen.
Pro Zielattribut werden zwei Größen kombiniert:
- Füllrate — Anteil der Datensätze, in denen das Attribut einen nicht-leeren Wert hat.
- Konformitätsrate — Anteil der gefüllten Werte, die die Schema-Einschränkungen einhalten. Aktuell wird die Werteliste eines Attributs geprüft (sofern eine konfiguriert ist). Hat ein Attribut keine Einschränkung, gilt die Konformität als 1.0.
Pro Attribut ergibt sich daraus:
dqi_attribut = Füllrate × Konformitätsrate
Die Gesamtkennzahl ist der gewichtete Mittelwert über alle Schema-Attribute, skaliert auf 0–100. Bestimmte Attribute werden dabei doppelt gewichtet (Faktor 2 statt 1):
- Attribute, die im Schema als Pflichtfeld markiert sind. Bleiben diese leer, wirkt sich das doppelt auf den DQI aus.
- Attribute mit einer Werteliste, wenn in der Operation die Option “Ergebnis auf Schemaattribute filtern” aktiv ist. Werte außerhalb der Liste sollen in diesem Modus gar nicht erst auftauchen — wenn sie es doch tun, zählt das doppelt.
Treffen beide Regeln auf dasselbe Attribut zu, bleibt die Gewichtung bei 2 (sie summiert sich nicht weiter auf).
Was der DQI nicht leistet
- Er bewertet nicht die inhaltliche Korrektheit eines Wertes. Ein KI-Modell, das mit einem irreführenden Prompt durchgehend plausible, aber falsche Werte erzeugt, kann trotzdem einen hohen DQI erreichen.
- Er ersetzt keine Stichprobenkontrolle. Sehen Sie ihn als ergänzendes Signal — ein DQI-Anstieg nach einer Prompt-Änderung ist ein Hinweis darauf, dass die Änderung struktureller Hinsicht etwas verbessert hat, kein Beweis, dass die Daten inhaltlich besser geworden sind.
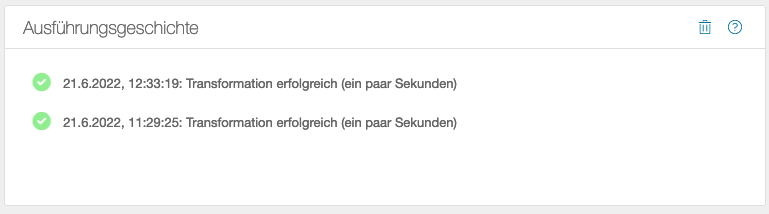
Historie
Jede Operation führt eine Historie ihrer letzten Ausführungen:
-
 Die Aktion war erfolgreich
Die Aktion war erfolgreich -
 Die Aktion läuft im Moment
Die Aktion läuft im Moment -
Die Aktion wurde abgebrochen
Über das ![]() Symbol kann die Historie geleert werden.
Symbol kann die Historie geleert werden.
Data Exploration
Wie bereits erwähnt, kann jede Operation in Chioro einzeln ausgeführt werden. Dies wird dadurch ermöglicht, dass die Produktdaten auf Ihrem Weg durch die Operationen (standardmäßig) jeweils nach jeder Operation zwischengespeichert werden. Diese zwischengespeicherten Daten sind durchsuchbar und können darüber hinaus visualisiert und analysiert werden.
Hierfür gibt es den Data Explorer welcher sich direkt unter dem Operation Editor befindet.
Im Data Explorer können über Schalter unterschiedliche Datentabellen eingeblendet werden. Welche das sind, hängt ein wenig von der gerade ausgewählten Flow-Operation ab, aber meist handelt es sich um …
- die Quelldaten der Operation, oder anders gesagt, das Ergebnis oder die Ergebnisse der Vorgängeroperation(en) (folglich nicht bei Datenquellen, welche ja keinen Vorgänger haben)
- das Ergebnis oder die Ergebnisse der Operation, oder anders gesagt, die Eingabedaten der folgenden Operation(en) (folglich nicht bei Datenzielen, welche ja keinen Vorgänger haben)
- die Ergebnisvorschau der Operation (ebenso nicht bei Datenzielen)
- weitere, beliebig auswählbere Ergebnisdaten anderer Operationen oder die Daten von Datentabellen. Diese können durch das “+” hinzugefügt werden.

Da die Möglichkeiten des Data Explorer recht umfangreich sind, ist diesem ein eigener Abschnitt der Dokumentation gewidmet.